
Как посмотреть историю сайта в Веб-архиве (Web Archive)
В последние годы всех поражает скорость, с которой развивается пространство в интернете. Регулярно обновляется дизайн сайтов, добавляются новые вкладки на веб-ресурсах, появляются новые онлайн-проекты. Этот процесс настолько головокружительный, что порой в стремительном потоке обновлений теряется важная информация. И тогда вспоминают об одном из способов найти желаемое — посмотреть, как выглядел сайт раньше, вернуться к его предыдущим версиям. История сайта проливает свет на то, как развивался проект, дает представление о надежности домена, если рассматривается вопрос его покупки. В этом материале мы расскажем, что такое веб-архивы и как ими пользоваться.

Почему важно знать историю сайта
В цифровую эпоху очень сложно совершить какое-либо действие, при этом не оставив цифрового следа. Это напрямую касается работы с сайтом. Фиксируются любые изменения, внесенные в его структуру. Сохраняется информация о том, как менялась тематика публикаций, какой контент размещался на отдельных страницах, подвергался ли веб-ресурс санкциям Google и многое другое.
Доступ к этим данным особенно полезен для тех, кто:
- занимается продвижением веб-ресурса;
- хочет создать новую контент-стратегию и стремится понять, как развивался проект ранее;
- планирует покупку домена;
- ищет данные, удаленные из общего доступа, например при подготовке журналистского расследования;
- хочет восстановить информацию после кибератаки.
Доступ к прежним версиям дает веб-архив сайтов. С его помощью специалисты разного профиля смогут узнать:
- как сайт выглядел в разные периоды;
- какую тематику имел онлайн-проект в разное время;
- какова история домена и сколько владельцев сменилось;
- попадал ли веб-ресурс под штрафные санкции.
Надеемся, мы убедили вас в важности того, что история веб-сайтов имеет большую ценность. Так что наш следующий шаг — научиться извлекать нужные данные.
Каков принцип работы веб-архивов
Практически сразу после роста числа сайтов возникла идея сохранить их для истории — так появился веб-архив. К примеру, крупнейший из них — Internet Archive — был основан в 1996 году, а сохраненный контент стал доступен с 2001 года. Одним из главных принципов создателей является идея «борьбы с исчезающими ссылками».
По сути, веб-архив — это крупнейшая база данных, в которой фиксируется состояние сайтов на определенный момент времени. То есть специальные веб-сканеры время от времени «посещают» интернет-страницы, создают их копии и сохраняют в своем архиве. Такая копия (или «слепок») привязывается к конкретной дате. Если пользователя заинтересовала идея посмотреть архив сайта, он может с помощью специальных сервисов увидеть, как выглядел ресурс в конкретный день, и проследить, как он менялся со временем.
К примеру, популярный сайт Wikipedia, основанный в январе 2001 года, в июле того же года имел всего 6 000 статей и выглядел так:
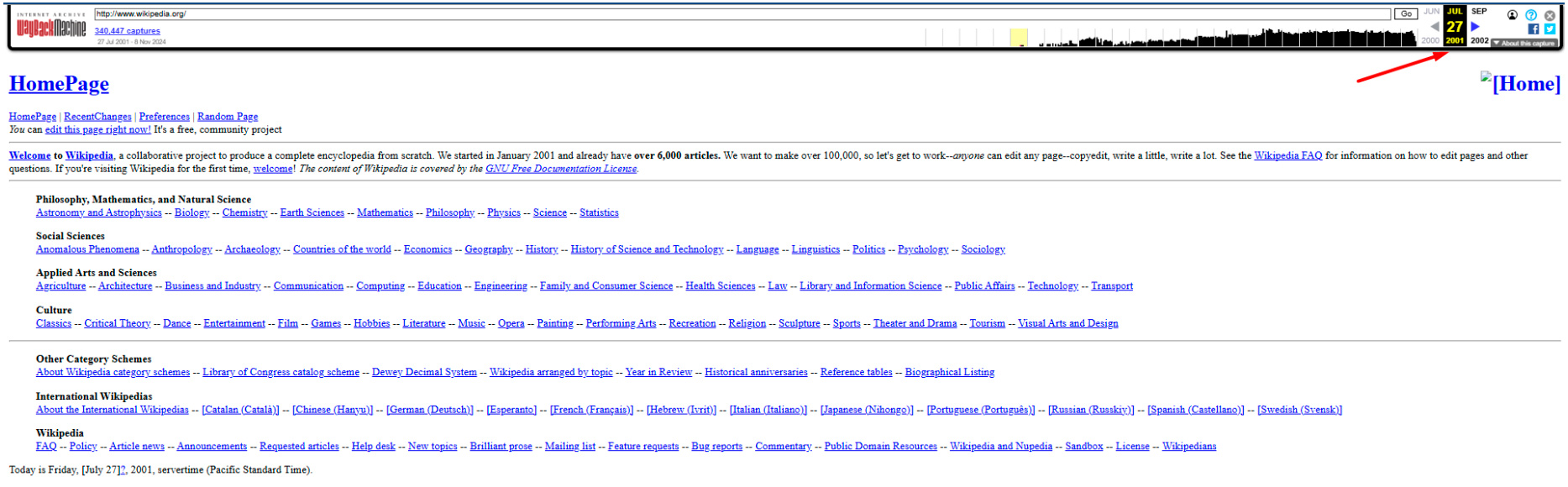
Правда, если создатели ограничат доступ к архивированию, то копии страниц могут не сохраниться.
Сервисы для проверки истории сайта и их использование
Найти архив сайта в открытом доступе можно с помощью специальных сервисов.
Webarchive
Когда пользователя интересует история сайта, архив на web.archive.org является наиболее информативным и удобным инструментом. Не зря его еще назвали Wayback Machinе. Этот сервис действительно как настоящая «машина времени» для веб-ресурса.
Например, вы хотите посмотреть старую версию сайта нашей агенции. Для этого введите наш адрес в поисковую строку и нажмите Enter.
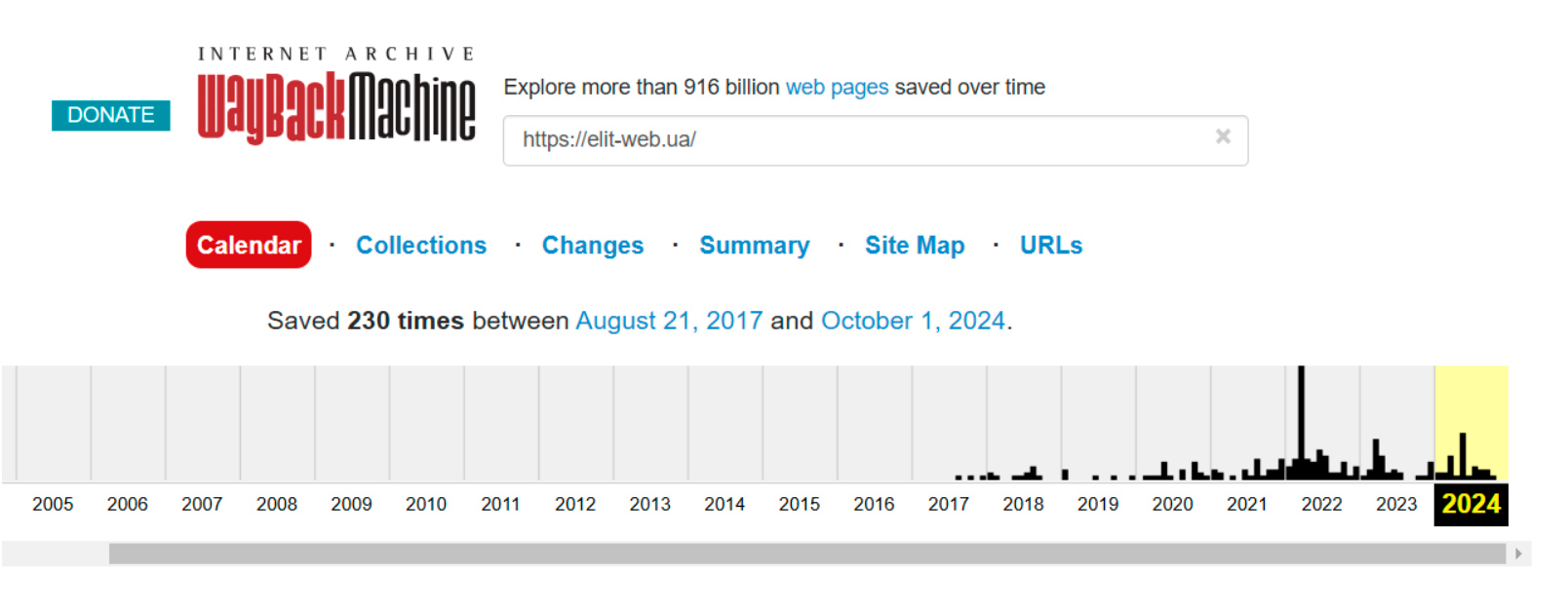
Открывшаяся «лента времени» покажет, что наш веб-ресурс был создан в августе 2017 года и с тех пор постоянно развивался. Одно из последних сканирований материала сайта состоялось 1 октября 2024 года.
Если вас интересует конкретная версия сайта, например за 2023 год, вы можете кликнуть на нужный год, и откроется календарь, где будут отмечены даты сканирования.
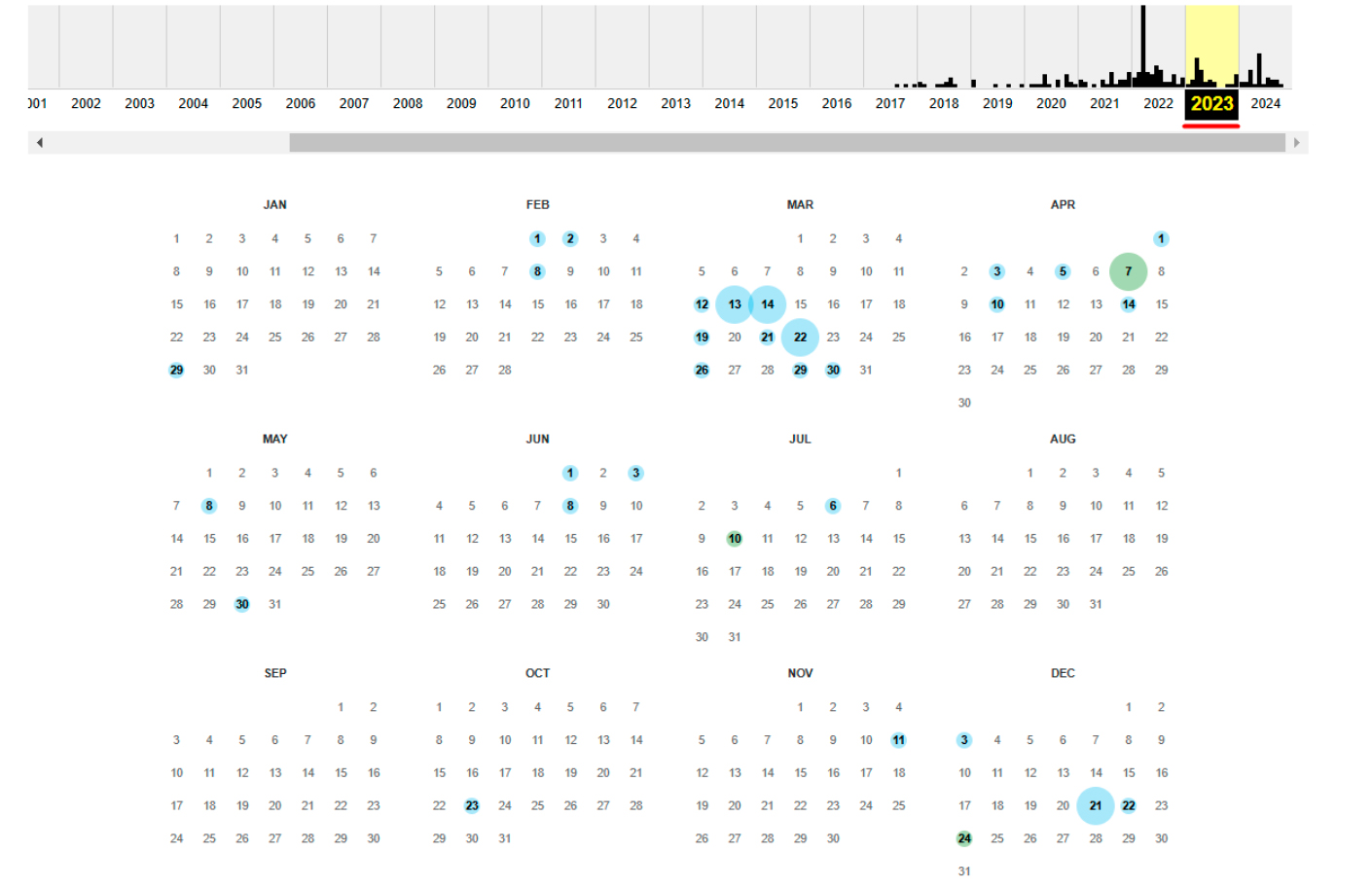
Или если вы хотите посмотреть, как сайт выглядел в прошлом, например в апреле 2022 года, выберите эту дату в календаре, и откроется архивная страница.

После перехода по ссылке вы увидите, как выглядел сайт в то время, и сможете просмотреть контент, размещенный на страницах.

На другой странице сервиса открывается доступ к информации об изменениях карты сайта.

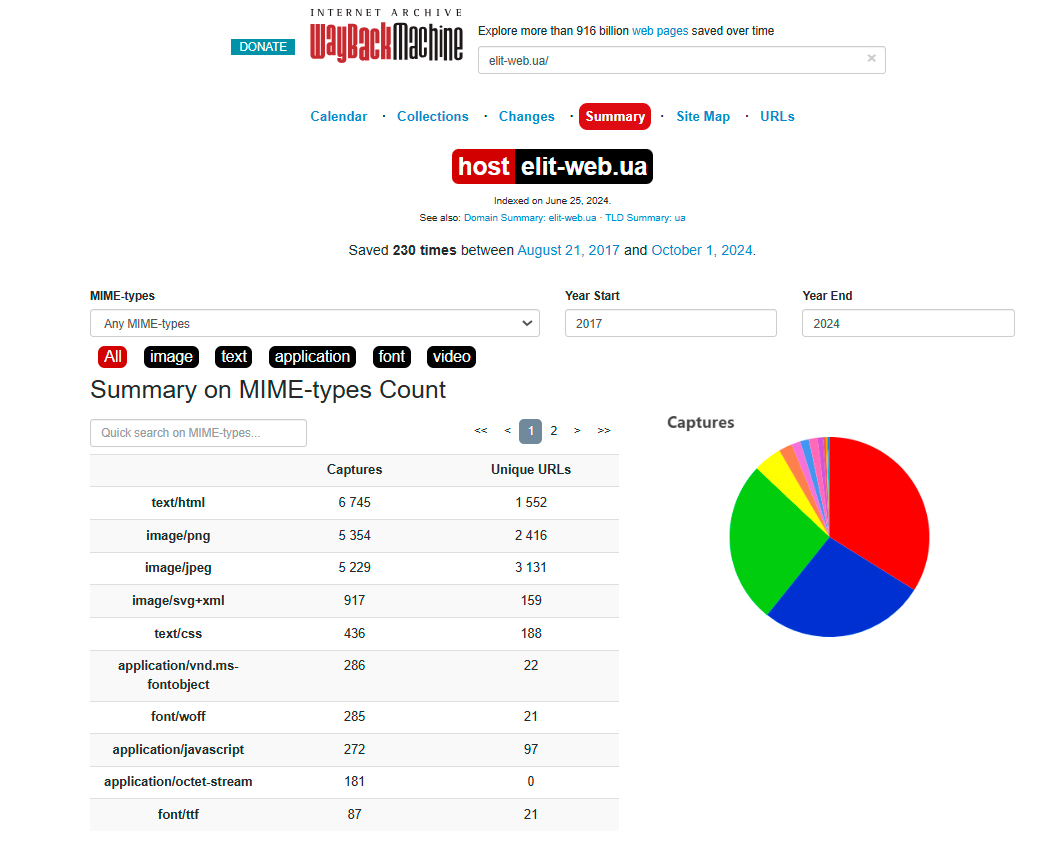
О соотношении типов контента, представленного на сайте, можно узнать через другую вкладку популярного сервиса.
Whois
Если предыдущий инструмент дает возможность посмотреть историю сайта, то Whois больше предназначен для проверки истории доменных имен. С его помощью вы сможете узнать:
- свободно ли доменное имя, если вы, например, планируете создать новый проект;
- подвергался ли существующий домен штрафным санкциям;
- когда был зарегистрирован домен и когда заканчивается период регистрации;
- где находятся серверы, на которых он размещен.
Сервис Whois — это своего рода архив доменов. Он очень прост в использовании: достаточно ввести адрес в поисковую строку, и откроется страница, на которой будет представлена полная информация о доменном имени.
Можно ли восстановить сайт из веб-архива и как это сделать?
Большой плюс сервиса, сохраняющего информацию обо всем, что было размещено на сайте ранее, — это возможность найти нужную версию веб-ресурса и восстановить ее. Так что специалисты могут не только посмотреть историю сайта, но и использовать найденные данные в своей работе.
Для начала нужно найти в веб-архиве интересующий вас вариант сайта. В этом поможет календарь, о котором мы уже рассказали выше. Если нужны отдельные тексты, изображения и другая подобная информация с предыдущих версий, их можно скачать в браузере после открытия нужной страницы. Ранее было возможно скопировать полностью старую версию страницы. Но после масштабной утечки данных осенью 2024 года функция сохранения интернет-страниц с помощью их URL-адресов временно закрыта.
Для восстановления сайта целиком лучше всего использовать сторонние онлайн-инструменты, например:
- Archivarix;
- Wayback Machine Downloader и некоторые другие.
На этих сервисах есть функции сохранения отдельных страниц или всего веб-ресурса. В последнем случае на почту приходит письмо с заархивированными данными, после чего сайт можно разместить на сервере и работать с ним.
Можно ли найти уникальный контент в веб-архиве?
Понимая, что каждый день из сети исчезают десятки ресурсов, вполне логично предположить, что вместе с этим теряется и ценная информация. Иногда владельцы веб-ресурсов сознательно удаляют компрометирующие их данные. В то же время другие пользователи могут захотеть, чтобы история страницы стала доступной широкому кругу. Это, например, актуально, когда проводится журналистское расследование.
Какова бы ни была причина, вопрос восстановления утерянного контента остается актуальным.
Если вы ищете просто ценный контент на определенную тему, самый трудоемкий этап — поиск исчезнувших ресурсов. В этом вам помогут сервисы со списками недавно освободившихся доменов, например ExpiredDomains.net. Далее будет проще. Вы можете просматривать сохраненные версии сайтов и искать нужный контент.
Журналисту, желающему проверить историю сайта и найти удаленные данные, будет проще: он уже знает, какой ресурс ему нужен. Далее можно просто искать предыдущие версии сайта в веб-архиве.
Можно ли сделать так, чтобы сайт не попал в библиотеку веб-архива?
С учетом последних новостей об утечке данных из веб-архива, а также по другим причинам разработчики могут задуматься о том, что архив веб-страниц — это не такое уж безопасное дело. Если у вас возникли подобные опасения, предлагаем способ, как запретить создание архивных копий.
Для этого нужно в файл robots.txt добавить команду, которая запрещает ботам-архиваторам доступ к сайту.

Дополнительно можно добавить noarchive в микроразметку заголовка.
Если вы хотите удалить сохраненный сайт из Internet Archive, оставьте запрос об этом на странице техподдержки с указанием причин такого решения. Вас уведомят о принятом решении.
Итоги
Надеемся, что вы разобрались вместе с нами, как посмотреть сайт в прошлом. Помните: если с вашим сайтом что-либо произойдет, его копии останутся в архиве, и вы сможете найти и восстановить утерянные данные.
Гузенко Светлана



