
Як корисний контент Google та інші системи штучного інтелекту можуть вплинути на видимість вашого сайту
Штучний інтелект змінює те, як ми шукаємо та знаходимо інформацію в інтернеті. Google, піонер у цій галузі, постійно тестує нові технології на основі ШІ для покращення результатів пошуку. Починаючи з Search Generative Experience (SGE) і закінчуючи інтеграцією технології чату Google Bard AI в різні продукти Гугл, штучний інтелект змінює наш пошуковий досвід.
Але що це означає для видимості сайту у видачі? Якщо ви помітили незрозуміле зниження органічного пошукового трафіку, є велика ймовірність, що система корисного контенту Google, керована штучним інтелектом, впливає на рейтинг вебресурсу. Вона використовує машинне навчання, щоб передбачити, чи буде інформація потрібна користувачу. Якщо буде виявлено, що на більшості сторінок контент не відповідає вимогам, сайт може бути класифікований як «некорисний».
У цій статті ми розповімо про те, як штучний інтелект уже кардинально змінив систему ранжування Google і що можна зробити, щоб вебресурс не втратив свої позиції.

Нагадаємо, мета Гугл — надати користувачу сторінки, які можуть бути йому корисні та задовольнять його очікування. Система досягає цієї мети, використовуючи складну інтеграцію моделей машинного навчання для створення сигналів, які Google застосовує в алгоритмах ранжування.
І ще хочемо зайвий раз нагадати, що коли справа доходить до сортування сайтів у видачі, то немає нічого більш важливого, ніж відповідність критеріям якості Гугл, які викладені в документації зі створення корисного контенту.
Еволюція алгоритмів Google і роль ШІ
Трансформація в систему, яка генерує відповіді та керується штучним інтелектом, завжди була метою Google. Місія корпорації полягає в тому, щоб зробити світову інформацію доступною й корисною. У 2000 році співзасновник Google Ларрі Пейдж сказав:
«Штучний інтелект стане остаточною версією Google. Так ми отримаємо досконалу пошукову систему, яка буде розуміти все в інтернеті. Вона точно зрозуміє, що ви хочете, і дасть вам те, що потрібно. Це і є штучний інтелект».
У 2013 році цю думку продовжив керівник пошуку Google Аміт Сінгхал. Він заявив, що «комп’ютери будуть знати, чого хочуть люди, і користувачам не доведеться вводити свої запити в маленьке віконце на чистій білій сторінці». За його словами, «доля пошуку — стати тим самим комп’ютером із “Зоряного шляху”, і саме його ми створюємо».
Google також заявила, що вже тривалий час використовує штучний інтелект для поліпшення алгоритмів, а саме з 2016 року.
На тепловій карті, створеній доктором Пітом із MOZ, видно: що «гарячіше» або ближче до червоного кольору смуга, то більше турбулентності було в результатах пошуку Гугл в той час. Було б справедливо припустити, що компанія почала використовувати ШІ у своїх алгоритмах наприкінці 2016 року. А яка важлива подія відбулася в цей час?
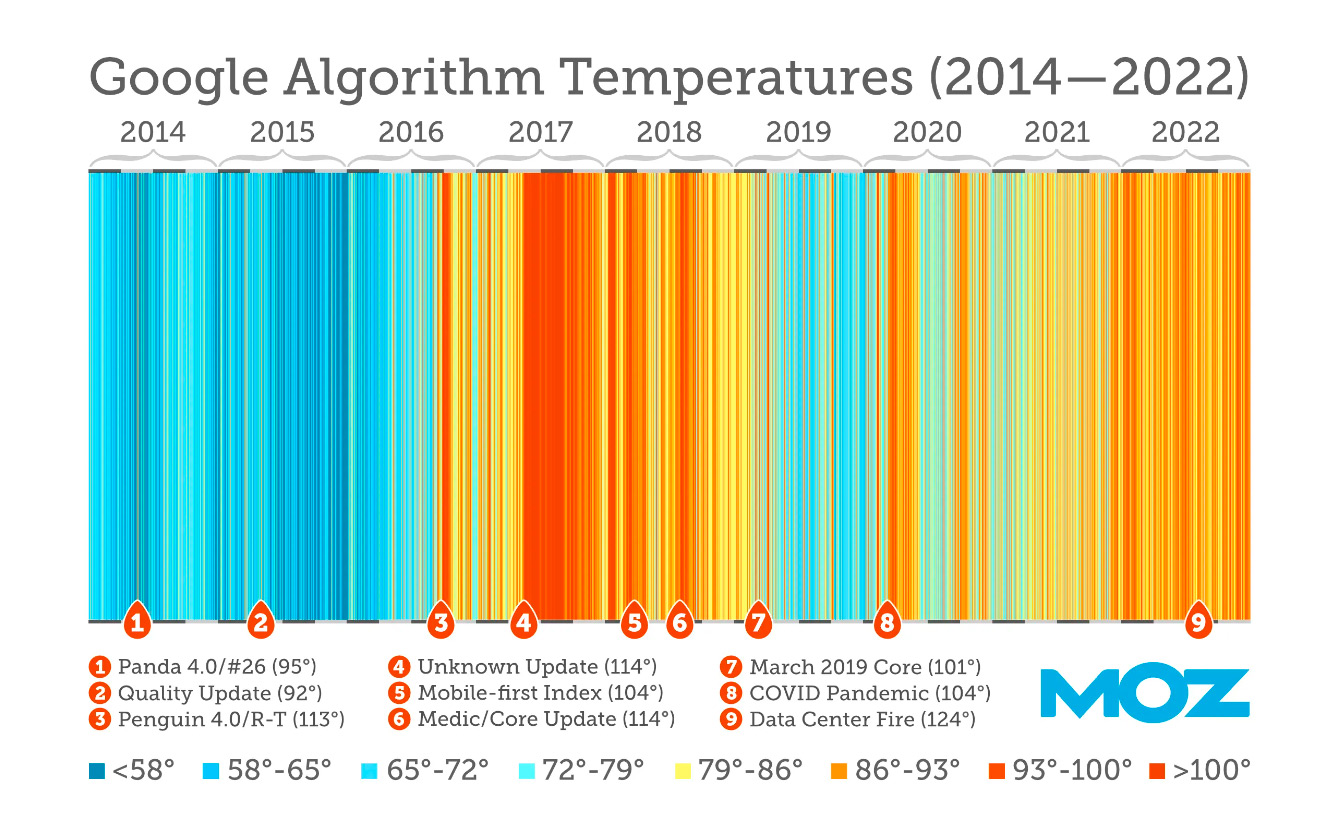
Під номером 3 на цій карті позначене оновлення Google Penguin 4.0 2016 року. Під час цього апдейту Гугл повідомила, що система може ігнорувати неприродні посилання замість того, щоб алгоритмічно придушувати сайти, які їх створили.
Також цікаво зазначити, що початкове розгортання Penguin відбулося лише за пару тижнів до того, як Google запустила Knowledge Graph («Мережу знань»). А ця технологія, зі свого боку, важлива для ШІ. Оголошення Google про чат-бот Bard також говорить нам, що він поєднує в собі силу, інтелект і креативність мовних моделей із «широтою світових знань». Ймовірно, це Knowledge Graph.
Тож що більше Google використовує системи штучного інтелекту, то важливішою для нас стає відповідність контенту, який вони заохочують.
Як системи ранжування Google використовують штучний інтелект для генерації сигналів
Декілька систем ранжування Google використовують машинне навчання, підмножину ШІ, для генерації сигналів. Вони відіграють вирішальну роль у визначенні того, які сайти розміщуються вище в результатах пошуку.
Уточнимо: сигнал — це частина інформації, яку алгоритми Google можуть використовувати для прийняття рішення про те, який контент варто класифікувати вище. Одним із прикладів таких даних є кількість якісних посилань, що ведуть на певну сторінку.
Генерує ці сигнали так звана Helpful Content System (система корисного контенту) Google.
Роль системи корисного контенту в генерації сигналів
Система корисного контенту використовує ШІ для генерації сигналу. За допомогою нього Гугл маркує контент, який має «малу цінність, низьку додану вартість», або, іншими словами, є некорисним для людей. Ці дані, разом із багатьма іншими, враховуються у процесі ранжування.
Якщо ваш трафік зменшується, це може бути результатом того, що система корисного контенту визначає більшу частину інформації як не найцікавіший результат для користувача. Такий процес оцінювання виконується безперервно та впливає на рейтинг сайту протягом декількох місяців, а це означає, що зміни можуть відбутися в будь-який час, а не тільки у зв’язку з анонсованими оновленнями.
По суті, система сигналізує: «Загалом контент з цього ресурсу — не найкорисніший варіант для пошуку в порівнянні з іншими». Така ситуація може бути серйозною перешкодою, яка не дозволяє сайту повністю реалізувати свій потенціал.
Дійсно, якщо глибше проаналізувати вміст сторінок, яким алгоритми Google віддають перевагу, і порівняти їх із тими, що ранжуються нижче, стає видно, що перші явно корисніше й інформативніше.
Можливо, вони швидше відповідають на запит або ведуть користувача до товару, який він хоче придбати. Можливо, на них є якісні зображення або таблиці. Часто Google показує вище сайт компанії, яка має реальний світовий досвід або пропонує інноваційний підхід до теми. Контент, який система позначає як гідний для високого ранжування, несе особливу цінність і оригінальний погляд в порівнянні з іншими сторінками в інтернеті.
Ось декілька прикладів, які можна зустріти на сайтах:

Як генерують сигнали системи виявлення спаму
SpamBrain — це система штучного інтелекту, яка здатна виявити спроби маніпулювання пошуком. Тепер вона може генерувати сигнал, який вказує на те, що сайт бере участь у маніпулятивних схемах із метою підвищення ранжування.
Якщо ваш ресурс знизив позиції з 14 грудня 2022 року, можливо, винне грудневе оновлення. Завдяки апдейту SpamBrain Google став краще визначати, на які сайти ведуть посилання з заспамлених майданчиків.
Це викликає багато запитань. Наприклад, чи варто використовувати Disavow Links Tool для відхилення посилань? У деяких випадках так, особливо якщо ви створили їх для цілей SEO.
Але сайтам, на які вплинуло це оновлення, інструмент навряд чи допоможе. У багатьох випадках втрати означають, що не сам ресурс був класифікований як спам, а під таке визначення потрапили майданчики, які посилаються на нього, що призводить до втрати цінності зворотних посилань.
Однак важко визначити, почалися втрати позицій саме під час цього апдейту або вони були пов’язані зі змінами в системі корисного контенту, оскільки обидва процеси відбувалися одночасно.
Наприклад, на цей сайт, можливо, вплинуло спам-оновлення від 14 грудня. Але втрати почалися у зв’язку з апдейтом системи корисного контенту від 5 грудня.
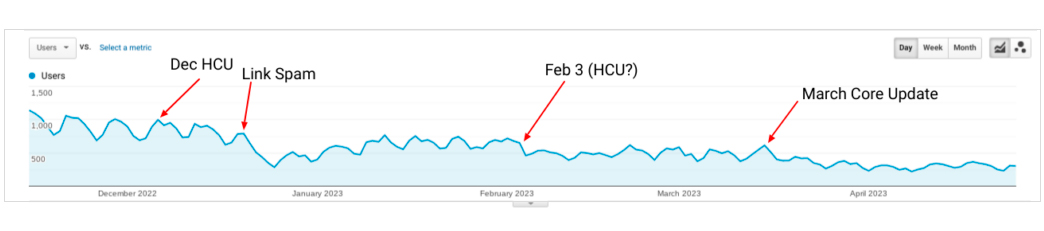
На цей сайт вели багато зворотних посилань, які явно були розміщені з метою SEO-просування. У цьому випадку краще відхилити ці лінки. Але, швидше за все, позиції вебресурсу навряд чи швидко покращаться.
Отже, пропонуємо кілька рекомендацій, що робити, якщо на рейтинг сайту вплинули спам-системи Google:
- якщо ви створили посилання для цілей SEO та бачите, що трафік почав зниження з 14 грудня 2022 року, варто подумати про використання Disavow Links Tool, щоб Гугл не враховував ці лінки у своїх алгоритмах. Можливо, на сайті є класифікація спаму. Правильне використання Disavow Links Tool може видалити її;
- якщо ви раніше займалися лінкбілдингом і спостерігаєте зменшення трафіку для сторінок, на які були спрямовані ці посилання, можливо, на вашому вебсайті немає класифікації спаму. Імовірніше, майданчики, з яких здійснювався перехід на ваш ресурс, були марковані як учасники маніпулятивних схем, і лінки на них були нейтралізовані. У таких випадках не варто виконувати відхилення посилань за допомогою Disavow Links Tool;
- якщо ви не впевнені, чи варто використовувати вищевказаний інструмент, краще витратьте час на підвищення корисності, цінності матеріалів на сайті.
Як система ранжування відгуків оцінює якість контенту
Система ранжування відгуків — це ще один інструмент машинного навчання на основі AI, який оцінює будь-який контент, що містить думку про продукт або аналізує його. Підкреслимо — будь-який, а не тільки огляди товарів. Ця модель «спрямована на те, щоб знайти й гідно оцінити огляди високої якості, тобто контент, що містить глибокий аналіз, оригінальні дослідження та написаний експертами або ентузіастами, які добре розбираються в темі».
Система ранжування відгуків оцінює матеріали на рівні сторінок. Але якщо у вас є значна кількість контенту, який ця система визнала неповноцінним, ви можете отримати сигнал в масштабах усього сайту. Якщо ви постраждали від оновлення системи ранжування відгуків після 12 квітня 2023 року, то, можливо, алгоритми машинного навчання Google вважають, що ваші матеріали менш корисні, ніж інші.
Складності основних оновлень Google
Основні оновлення Google спрямовані на заохочення контенту, цінного для користувачів. Компанія надає рекомендації зі створення матеріалів, орієнтованих на людей, і пропонує список критеріїв, які необхідно враховувати.
Ми рекомендуємо ретельно вивчити документацію Google про корисний контент. Це критерії, за якими працюють алгоритми ранжування.
Panda: генезис моделей якості Google
Вперше ми побачили версію цих критеріїв в оголошенні про алгоритм Panda у 2011 році. У цьому документі Google заявила: «Саме такі запитання ми ставимо собі, коли пишемо алгоритми, які намагаються оцінити якість сайту».
Коли Panda вперше розгорнули, SEO-спільнота зрозуміла, що це повпливає на сайти з явно неповноцінним контентом. Але мало хто тоді міг передбачити, що Google колись зможе використовувати ШІ для створення моделі, що визначає якість і користь інформації на вебресурсі.
У 2011 році компанія опублікувала таку інформацію про Panda:
«Наші алгоритми оцінювання якості сайтів спрямовані на те, щоб допомогти людям знаходити “високоякісні” сайти шляхом зниження рейтингу низькоякісного контенту. Нещодавнє оновлення Panda розв’язує складне завдання алгоритмічного оцінювання якості сайту. Зробивши крок назад, ми хотіли б пояснити деякі ідеї та дослідження, які лежать в основі розроблення наших алгоритмів.
Нижче наведені запитання, які можна використовувати для оцінювання “якості” сторінки або статті. Саме такі запитання ми ставимо собі, коли пишемо алгоритми, які намагаються оцінити якість сайту. Вважайте, що ми намагаємося закодувати те, що, на нашу думку, потрібно нашим користувачам.
Звичайно, ми не розкриваємо реальні сигнали ранжування, що використовуються в наших алгоритмах, оскільки ми не хочемо, щоб користувачі грали з результатами пошуку; але якщо ви хочете краще зрозуміти мислення Google, то наведені нижче запитання дадуть деяке уявлення про те, як ми розглядали цю проблему:
- Чи довіряєте ви інформації, представленій у цій статті?
- Ця стаття написана експертом або ентузіастом, який добре знає тему, чи вона має поверхневий характер?
- Чи є на сайті статті, які повторюються, перекриваються або є зайвими, мають однакові або подібні теми з дещо різними варіантами ключових слів?
- Чи буде безпечно залишати інформацію про свою кредитну картку на цьому сайті?
- Чи є в цій статті орфографічні, стилістичні або фактичні помилки?
- Теми були визначені відповідно до реальних інтересів читачів сайту чи сайт генерує контент у спробах вгадати, що може добре ранжуватися в пошукових системах?
- Чи містить стаття оригінальний контент або інформацію, оригінальні звіти, оригінальні дослідження або оригінальний аналіз?
- Чи має сторінка істотну цінність у порівнянні з іншими сторінками в результатах пошуку?
- Наскільки ретельно контролюється якість контенту?
- Чи описуються у статті обидві сторони історії?
- Чи є сайт визнаним авторитетом у своїй темі?
- Чи виробляється контент масово, передається на аутсорсинг великій кількості авторів або розподіляється за великою мережею сайтів, щоб окремі сторінки або сайти не отримували стільки уваги?
- Стаття добре відредагована чи виглядає недбалою, зробленою наспіх?
- Довірилися б ви інформації, отриманій з цього сайту, якби йшлося про здоров’я?
- Чи визнали б ви цей сайт авторитетним джерелом у разі згадування його назви?
- Чи дає ця стаття повний або вичерпний опис теми?
- Чи містить ця стаття глибокий аналіз або цікаву інформацію, яка не є очевидною?
- Чи хотіли б ви додати цю сторінку в закладки, поділитися нею з другом або порекомендувати її?
- Чи немає в цій статті надмірної кількості реклами, що відвертає увагу від основного контенту або заважає йому?
- Чи очікували б ви побачити цю статтю у друкованому журналі, енциклопедії або книзі?
- Чи є статті короткими, беззмістовними або такими, що не містять корисної інформації?
- Сторінки створювалися з великою скрупульозністю й увагою до деталей або ж уваги до деталей мало?
- Чи будуть користувачі скаржитися, якщо побачать сторінки цього сайту?
Написання алгоритму для оцінювання якості сторінки або сайту — набагато складніше завдання, але ми сподіваємося, що наведені вище запитання дадуть деяке уявлення про те, як ми намагаємося писати алгоритми, які відрізняють сайти вищої якості від сайтів нижчої якості».
Фільтр Panda від Google став катастрофою для багатьох вебресурсів. Були розроблені розпливчасті теорії щодо відновлення, які зводилися, по суті, до «видалення, об’єднання або поліпшення неповноцінного контенту».
Однак мало хто розглядав поради Google щодо підвищення якості як щось, що можна виміряти алгоритмічно. У той час SEO-спільнота не могла припустити, що штучний інтелект буде використаний для докорінної трансформації методів оцінювання. Завдяки використанню моделей машинного навчання алгоритми тепер можуть інтерпретувати величезну кількість сигналів, навчаючись визначати користь, актуальність і глибину інформації та відповідно коригувати ранжування.
Можна теоретично міркувати про те, як це відбувається, але ми точно знаємо, що заохочуються сайти, відповідні рекомендаціям Гугл щодо корисного контенту.
Пошук здійснюється на основі сотень алгоритмів і моделей машинного навчання
Google написала статтю про те, як ШІ впливає на результати пошуку. У ній, зокрема, сказано, що система заснована на роботі сотень алгоритмів і моделей машинного навчання. Кожен спрацьовує в різний час і в різних комбінаціях, щоб забезпечити найкорисніші результати.
У статті детально описано, як система глибокого навчання під назвою RankBrain використовується для ранжування сайтів. Її називають «однією з основних систем штучного інтелекту, що забезпечують роботу пошуку сьогодні». У статті також йдеться про нейронний підбір, який використовує ШІ для визначення ідеї, яку шукає користувач, і контенту, відповідного їй. Це вважається «великим стрибком вперед від розуміння слів до понять».
Якщо ви вже заплуталися, то все зводиться до цього: пошук працює на основі сотень алгоритмів і моделей машинного навчання, які генерують сигнали, що допомагають визначити, наскільки якісними й корисними є сторінки.
Ключ до ранжування — постійно бути найкориснішим результатом. Щоб ваш сайт був саме таким, необхідно враховувати кожен із критеріїв корисного контенту Google. Вони являють собою узагальнену версію керівництва з оцінювання якості пошуку.
Роль оцінювачів якості в алгоритмах машинного навчання
На сторінці Google «Як працює пошук» йдеться про застосування систем машинного навчання, які допомагають краще оцінювати релевантність. За словами представників компанії, для такого аналізу використовуються «дані про взаємодію» — від людей, які взаємодіють із пошуковою системою. Їх називають Quality Raters, або оцінювачами якості. Потім ці дані перетворюються на сигнали. Вище ми згадали декілька систем, що їх генерують, зокрема системи корисного контенту та ранжування відгуків.
Що ж являють собою ці дані про взаємодію?
У документації Google про те, як використовуються Quality Raters, згадуються два джерела.
Дані про взаємодію: роль пошуку в режимі реального часу
Експерименти в режимі реального часу допомагають моделям машинного навчання визначити, чи справляються вони зі своїм завданням щодо кращого розпізнавання корисного контенту. Якщо ні, то системи можуть дізнатися, яким характеристикам можна надати більшу вагу в алгоритмах, щоб досягти ще більших результатів.
Компанія Google хоче, щоб її моделі дійсно добре розпізнавали якісний контент. Для цього необхідно показати безліч прикладів корисних і некорисних результатів. Що більше їх, то краще модель передбачає правильне поєднання факторів, які необхідно враховувати для визначення якості.
Як Google отримує багато прикладів? У компанії є ціла команда людей, які їх надають.
Хто ці помічники? Це 16 000 оцінювачів якості.
Оцінювачі якості: визначення корисних і некорисних сторінок
У компанії Google є документ, який кожен SEO-фахівець повинен прочитати кілька разів, під назвою Quality Raters’ Guidelines (QRG, або керівництво для оцінювачів якості). По суті, це підручник, який допомагає оцінювачам зрозуміти, що саме дозволяє вважати контент корисним для людини. Ці рекомендації описують ті матеріали, які використовуються при створенні моделей штучного інтелекту.
Критерії кориcті контенту є узагальненою версією рекомендацій, запропонованих у QRG.
Маркування «корисно» та «некорисно» мають неоціненне значення для алгоритмів машинного навчання Google. Класифікуючи таким способом результати пошуку, оцінювачі якості надають реальний зворотний зв’язок, на якому алгоритми можуть вчитися.
Як визначається користь сторінки?
Quality Raters використовують шкалу оцінок, яка враховує, наскільки добре контент задовольняє потреби користувача. Вона складається з 2 частин.
|
Якість сторінки |
Задоволеність потребам |
|---|---|
|
Ключове питання: Наскільки добре сторінка досягає своєї мети |
Ключове питання: Наскільки корисним є результат для даного пошуку |
|
Визначте мету Оцініть, чи є сторінка шкідливою Визначте рейтинг |
Визначте намір користувача Визначте рейтинг |
Високоякісна сторінка — та, яка розуміє мету користувача й відповідає їй, не завдаючи шкоди, пропонуючи високоякісний і зручний досвід. Вона відповідає намірам людини, надаючи корисний і точний контент, а також дає значну цінність у відповідь на конкретний пошуковий запит.
Недостатньо просто мати декілька хороших сторінок. Google стверджує, що наявність достатньої кількості сторінок, класифікованих як некорисні, може призвести до зниження позицій всього сайту, зокрема якісних сторінок.
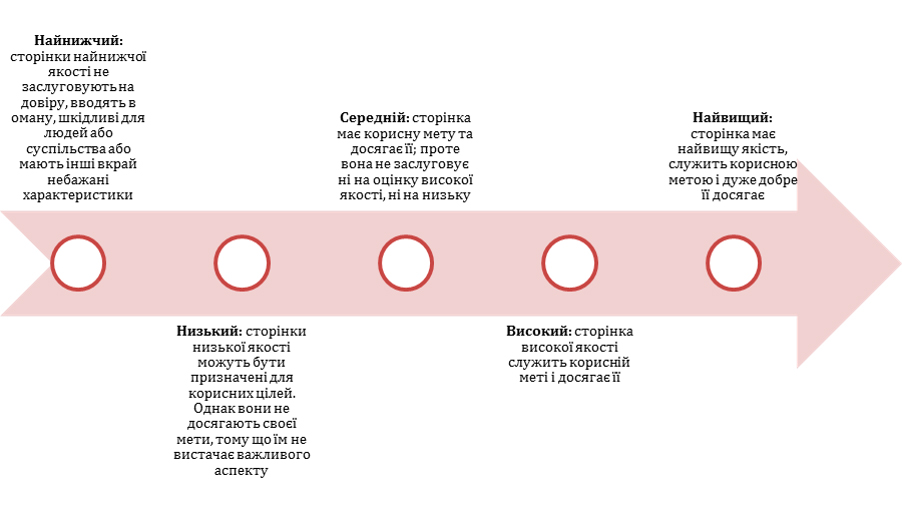
Якщо ви спостерігаєте погіршення пошукових показників, то цілком можливо, що ваш контент подає сигнали Google про те, що його слід вважати скоріше середнім за якістю на графіку вище, ніж високим. Він приносить користь. Він досягає своєї мети. Але найчастіше він не є найкращим варіантом для показу користувачам.
Якщо більша частина ваших сторінок така, ви можете зіткнутися з класифікатором корисного контенту. І він впливає на весь ваш сайт, а не тільки на низькоякісні матеріали.
Досить довгий час досвідчений SEO-фахівець міг домогтися багато чого за допомогою посторінкового SEO та нарощування посилальної маси, щоб поліпшити ранжування з середньою якістю контенту. Сьогодні ж моделі машинного навчання допомагають Google визначати, які сайти найбільшою мірою відповідають критеріям, що люди вважають корисними. Це значно ускладнює ранжування контенту середнього рівня. Він може служити корисній меті, але не заслуговує високої оцінки.
Два стовпи якості: E-E-A-T і задоволення потреб користувачів
Хоча запитання щодо корисного контенту та QRG дають нам багато інформації, створення якісних сторінок зводиться до двох компонентів: критеріїв E-E-A-T і, що ще важливіше, наскільки ви задовольняєте потреби користувачів.
E-E-A-T: наріжний камінь якості
Якість — це синонім E-E-A-T. Абревіатура розшифровується як Experience (досвід), Expertise (компетентність), Authoritativeness (авторитетність) і Trustworthiness (надійність). У QRG поняття E-E-A-T і «якість сторінки» — це, по суті, одне й те саме.
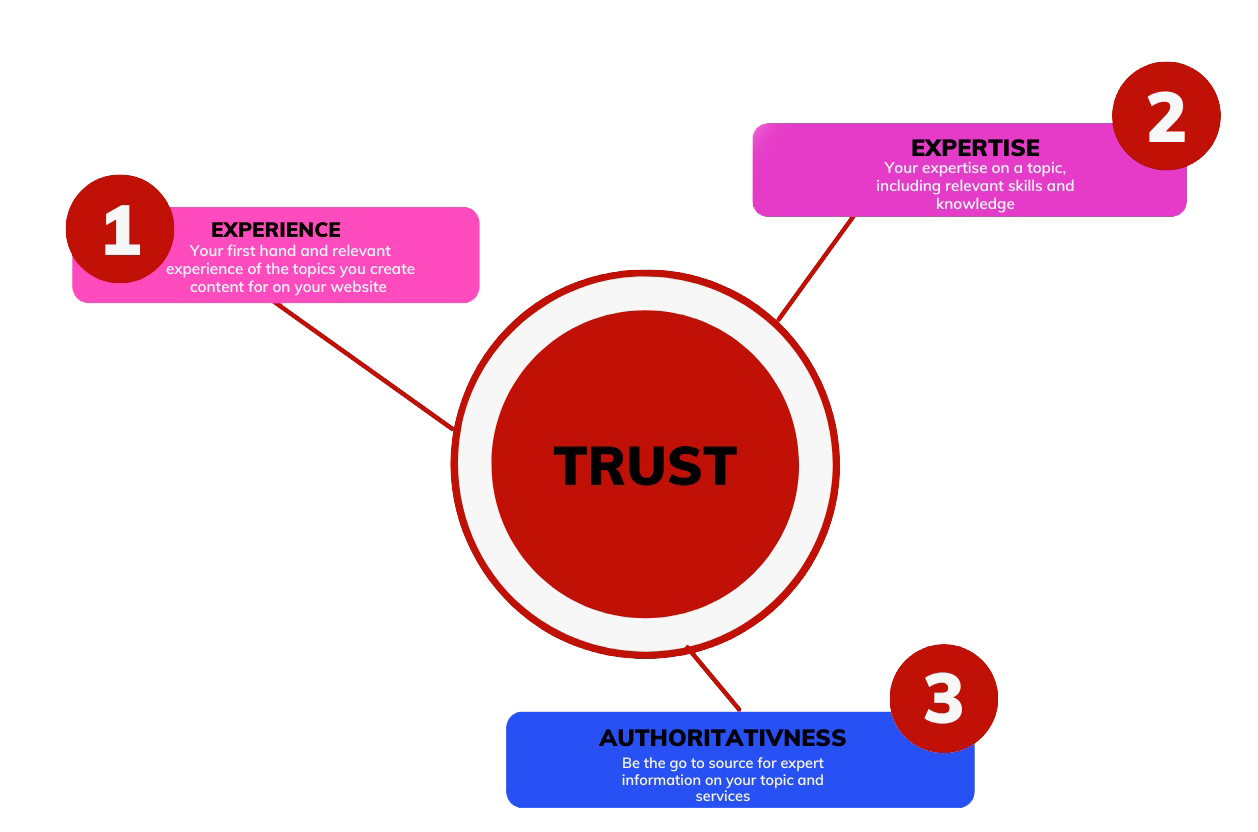
Ці критерії особливо важливі для сторінок, які стосуються здоров’я, фінансів або інших YMYL-тем.
Компанія Google заявила, що модель E-E-A-T враховується в кожному запиті. Але це лише частина рівняння. Також дуже важливо, чи будуть задоволені потреби користувача.
Протягом багатьох років сайти отримували перевагу в пошуку завдяки кращій демонстрації E-E-A-T. Зараз, навіть якщо ці критерії дотримані, сторінки можуть мати труднощі через те, що вони не так добре задовольняють потреби користувачів. І важливим компонентом тут є досвід взаємодії зі сторінкою.
Досвід взаємодії зі сторінкою: ключовий фактор задоволення потреб користувачів
У документації, присвяченій досвіду взаємодії зі сторінкою, Google стверджує, що якщо ми хочемо домогтися успіху в роботі з їхніми системами, то не повинні фокусуватися тільки на одному або двох аспектах. Тобто необхідно враховувати багато факторів.
Хоча всі вони впливають на прийняття рішення про те, наскільки хороший досвід надає сторінка, можна виділити найважливіший критерій: «Наскільки легко користувачі можуть орієнтуватися на сайті?».
Одна з найважливіших порад, яку можна дати щодо підвищення користі контенту:
- визначте, в чому полягає потреба користувача;
- замість того, щоб заповнювати верхню частину статті словами, які люди навряд чи читатимуть, задовольніть цю потребу як головний пріоритет.
Дуже багато сторінок, на які негативно вплинула система корисного контенту, містять масу слів, спрямованих не на користувачів, а на те, щоб показати пошуковим системам, що сторінка релевантна. Це неправильний підхід.
Висновок: навігація в новій ері пошукового ранжування на основі ШІ
Хоча на горизонті маячить безліч змін у пошуковій індустрії, пов’язаних із ШІ, нам слід звернути пильну увагу на те, як Google уже використовує його, зокрема машинне навчання, для підвищення релевантності та користі результатів видачі.
Якщо ваш трафік зменшується й ви не можете зрозуміти, чому, то є велика ймовірність того, що системи Гугл дізналися, що ваш контент не дуже корисний для задоволення потреб користувачів. Можливо, на сайті встановлена класифікація, яка перешкоджає його ранжуванню.
Попрацювавши над відповідністю ідеалам, описаним у керівництві для оцінювачів і узагальненим у критеріях корисного контенту Google, ми можемо підвищити свої шанси на те, що алгоритми вважатимуть наш ресурс корисним і релевантним результатом.
Для сайтів, що потрапили до категорії небажаного контенту, для відновлення необхідно видалити неякісні матеріали та поліпшити відповідність критеріям корисного контенту, а потім почекати кілька місяців, щоб класифікацію зняли.
FAQ
Враховуючи, що Google використовує штучний інтелект для створення моделей, які передбачають, наскільки корисним може бути контент, чи варто адаптувати SEO-стратегію, щоб зосередитися на створенні якісного контенту?
Для багатьох такий перехід означає значне збільшення витрат. Це важко виправдати, особливо для сайтів з великою кількістю контенту середньої якості, які, можливо, наразі відчувають труднощі.
Чи є сенс у лінкбілдингу?
Посилання все ще є важливою складовою E-E-A-T. Але багато з тих посилань, які намагаються отримати SEO-фахівці, найімовірніше, ігноруються алгоритмами Google. Посилання — це один із багатьох факторів, що враховуються в оцінюванні якості. Завдяки багаторічному досвіду Google розуміє, які з них слід використовувати як сигнали ранжування. Якщо ви можете отримати хороші, авторитетні посилання, які дійсно є рекомендаціями, то вони дають сигнал якості. Однак тільки їх недостатньо, щоб зробити сайт корисним.
Чи варто заглиблюватися далі в тему, щоб зрозуміти, як нейронні мережі Google визначають релевантність контенту?
Можливо, варто більше дізнатися про те, як посилати сигнали релевантності й авторитетності. Сайти можуть багато чого досягти, але не чорними методами, а створюючи дійсно корисний контент, відповідний їхній тематиці.
Як донести до своїх клієнтів інформацію про зміни в алгоритмах Google?
Багато речей, які робляться в SEO, можуть виявитися не такими важливими, як створення дійсно корисного контенту. Швидкий, технічно якісний сайт — це важливо. Але контент від цього якісніше не стає. Деякі види робіт з придбання посилань можуть допомогти поліпшити E-E-A-T. Але якщо контент середньої якості та рідко є найкращим варіантом для показу користувачам, то ніяке нарощування посилальної маси або технічні виправлення не допоможуть поліпшити ситуацію. Якщо вам потрібна допомога в оцінюванні того, чи впливає на ваш сайт система корисного контенту Google, звертайтеся до наших фахівців. Вони дадуть рекомендації щодо поліпшення якості вебресурсу та відновлення втраченого органічного пошукового трафіку.
Гузенко Світлана



