
Screaming Frog SEO Spider – повне керівництво зі сканування сайту
Screaming Frog SEO Spider – один із найважливіших інструментів в арсеналі оптимізатора. Цей сервіс просто незамінний при аналізі інтернет-ресурсу, оскільки дозволяє автоматизувати збір та структурування найважливіших даних про сайт, тим самим прискорюючи роботу.
Якщо ви займаєтеся розвитком власного веб-проекту або просуванням сайтів клієнтів, то Screaming Frog напевно вам знайомий. Але чи ви використовуєте доступні можливості на 100%? У цій статті ми підготували докладний посібник з використання цього інструменту. Сподіваємося, ви зможете знайти тут багато нового та корисного.
Базове сканування сайту
Як сканувати весь сайт
Починаючи сканування сайту, важливо наперед визначити, яку інформацію ви хочете отримати, наскільки великий сайт, і яку частину сайту вам потрібно сканувати, щоб отримати доступ до потрібних даних.
Примітка : Іноді для масштабних ресурсів краще обмежити сканер підрозділом URL-адрес, щоб отримати хороший репрезентативний зразок даних. Це робить розміри файлів та експорт даних більш керованими. Ми розглянемо це докладніше нижче.
Для сканування всього сайту, включаючи всі дочірні домени, потрібно внести невеликі зміни в конфігурацію spider, щоб почати.
За замовчуванням Screaming Frog сканує лише субдомен, який ви запровадили. Будь-які додаткові субдомени, з якими стикається spider, розглядатимуться як зовнішні посилання. Для обходу додаткових піддоменів необхідно змінити налаштування в меню Spider Configuration. Відзначивши Crawl All Subdomains, ви переконаєтеся, що SEO Spider сканує будь-які посилання, які він зустрічає на інші піддомени на вашому сайті.
Крок 1:

Крок 2:
Якщо ви запускаєте сканування з певної підпапки або підкаталогу і, як і раніше, хочете, щоб Screaming Frog сканував весь сайт, встановіть прапорець Crawl Outside of Start Folder.
За замовчуванням SEO Spider налаштований лише на сканування підпапки або підкаталогу, який ви скануєте. Якщо ви хочете сканувати весь сайт і запускати з певного підкаталогу, переконайтеся, що для конфігурації встановлено обхід за межами початкової папки.
Порада : Щоб заощадити час та місце на диску, пам’ятайте про ресурси, які можуть не знадобитися під час сканування. Зніміть прапорці із зображення, CSS, JavaScript та SWF-ресурсів, щоб зменшити розмір обходу.
Як сканувати один підкаталог
Якщо ви хочете обмежити сканування однією папкою, просто введіть URL-адресу та натисніть Start, не змінюючи жодних налаштувань за промовчанням. Якщо ви перезаписували початкові параметри за промовчанням, скиньте параметри за замовчуванням у меню File.

Якщо ви хочете почати сканування в певній папці, але потрібно продовжити сканування в інших частинах субдомену, обов’язково виберіть Crawl Outside Of Start Folder в налаштуваннях Spider Configuration, перш ніж вводити вашу конкретну стартову URL.

Як сканувати певний набір піддоменів або підкаталогів
Щоб обмежити перегляд певних наборів піддоменів або підкаталогів, можна використовувати RegEx, щоб встановити ці правила у параметрах Include або Exclude у меню Configuration.
Exclusion (Виняток)
У цьому прикладі ми переглянули кожну сторінку на elit-web.ru, за винятком сторінок blog на кожному піддомі.
Крок 1 :
Перейдіть до Configuration > Exclude, використовуйте підстановочні регулярні вирази для визначення URL або параметрів, які потрібно виключити.

Крок 2 :
Перевірте свій регулярний вираз, щоб переконатися, що він виключає очікувані сторінки до початку сканування:

Include (Включення)
У наведеному прикладі ми хотіли переглянути тільки підпапку команди на elit-web.ru. Знову ж таки, використовуйте закладку Test, щоб протестувати кілька URL і переконатися, що RegEx правильно налаштований для вашого правила inclusion.
Це чудовий спосіб сканування великих сайтів. Насправді, Screaming Frog рекомендує цей метод , якщо вам потрібно розділити та сканувати сайт з великою кількістю зворотних посилань.

Як отримати список усіх сторінок на моєму сайті
За замовчуванням Screaming Frog налаштований на сканування всіх зображень, JavaScript, CSS та флеш-файлів, з якими стикається SEO Spider. Щоб сканувати (crawl) тільки HTML, вам доведеться зняти виділення з пунктів Check Images, Check CSS, Check JavaScript та Check SWF у меню Spider Configuration.

Запуск SEO Spider з цими налаштуваннями без галочки по суті надасть вам список усіх сторінок вашого сайту, на які є внутрішні посилання, що вказують на них.
Після завершення сканування перейдіть на вкладку Internal і відфільтруйте результати HTML. Натисніть кнопку Export і у вас буде повний список у форматі CSV.

Порада : Якщо ви схильні використовувати ті самі налаштування для кожного сканування, Screaming Frog тепер дозволяє зберегти настройки конфігурації:

Як отримати список усіх сторінок у певному підкаталозі
На додаток до зняття прапорця Check Images, Check CSS, Check JavaScript та Check SWF, ви також захочете зняти прапорець Check Links Outside Folder у налаштуваннях Spider Configuration. Запуск SEO Spider з цими налаштуваннями без прапорця, дасть вам список усіх сторінок у вашій стартовій папці (якщо вони не є сторінками, на які немає внутрішніх або зовнішніх посилань).
Як знайти всі субдомени на сайті та перевірити внутрішні посилання
Є кілька різних способів знайти всі піддомени на сайті.
Спосіб 1
Використовуючи Screaming Frog для ідентифікації всіх піддоменів на цьому сайті, перейдіть у Configuration > Spider і переконайтеся, що вибрано опцію Crawl all Subdomains. Як і при скануванні всього сайту, це допоможе сканувати будь-який піддомен, пов’язаний з обходом сайту. Проте це не знайде піддоменів, які не пов’язані посиланнями.

Спосіб 2
Використовуйте Google (розширення для браузера Scraper Chrome) для ідентифікації всіх проіндексованих піддоменів, ми можемо знайти всі субдомени, що індексуються, для даного домену.
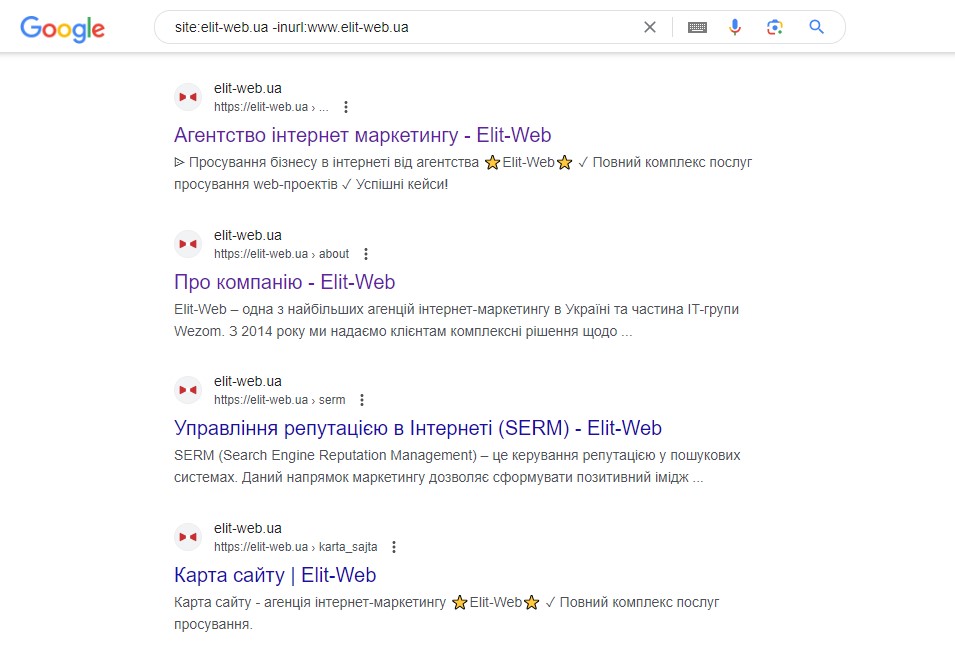
Крок 1 :
Почніть вводити в пошуковій системі: site: оператор пошуку в Google, щоб обмежити результати для вашого конкретного домену. Потім використовуйте оператор пошуку -inurl, щоб звузити результати пошуку, видаливши основний домен. З’явиться список піддоменів, проіндексованих у Google, в якому не буде основного домену.
Крок 2 :
Використовуйте розширення Scraper , щоб отримати всі результати в Google Sheet. Просто клацніть правою кнопкою миші URL-адресу в пошуковій видачі, натисніть Scrape Similar і експортуйте до Google Doc.
Крок 3 :
У документі Google Doc використовуйте таку функцію, щоб обрізати URL-адресу до субдомену:
=LEFT(A2,SEARCH («/»,A2,9))
Насправді, наведена вище формула повинна допомогти видалити будь-які підкаталоги, сторінки або імена файлів в кінці сайту. Ця формула дозволяє не експортувати в Excel те, що знаходиться ліворуч від кінцевої косої межі. Стартове число 9 є важливим, тому що ми просимо його почати шукати косу межу «/» після 9-го символу. Це складає протокол: https://, довжиною 8 символів.
Дублюйте список та завантажте його в Screaming Frog у режимі списку (List Mode) – ви можете вручну вставити список доменів, використовувати функцію вставки (paste) або завантажити (upload) CSV.

Спосіб 3
Введіть URL-адресу кореневого домену в інструменти (tools), щоб знайти сайти, які можуть існувати на тій же IP-адресі. Також можна скористатися пошуковими системами, спеціально призначеними для пошуку піддоменів, наприклад FindSubdomains. Створіть безкоштовний обліковий запис для входу та експорту списку піддоменів. Потім завантажте список Screaming Frog, використовуючи режим списку (List Mode).
Як тільки SEO Spider закінчить роботу, ви зможете побачити код стану, а також будь-які посилання на домашніх сторінках піддоменів, текст прив’язки та дублікати заголовків сторінок, серед іншого.
Як сканувати інтернет-магазин чи інший великий сайт
Спочатку Screaming Frog не був створений для сканування сотень тисяч сторінок, але завдяки деяким оновленням він стає багатофункціональнішим з кожним днем.
Останню версію Screaming Frog було оновлено, щоб покладатися на сховище бази даних для обходів. У версії 11.0 Screaming Frog дозволяв користувачам зберігати всі дані на диску у базі даних, а не просто зберігати їх у оперативній пам’яті. Це відкрило можливість сканування великих сайтів в один клік.
У версії 12.0 сканування автоматично зберігає обходи бази даних. Це дозволяє отримати доступ до них і відкрити за допомогою File > Crawls у меню верхнього рівня (на випадок, якщо ви дивуєтесь, куди пішла команда open?)
Хоча використання обходу бази даних допомагає Screaming Frog краще управляти більшими обсягами інформації, це, звичайно, не єдиний спосіб сканування великого сайту.
По-перше, ви можете збільшити виділення пам’яті у SEO Screaming Frog.
По-друге, ви можете розбити сканування за підкаталогом або сканувати лише певні частини сайту, використовуючи налаштування Include / Exclude.
По-третє, ви можете не сканувати зображення, JavaScript, CSS та flash. Скасувавши вибір цих параметрів у меню Configuration, заощадивши цим пам’ять, скануючи лише HTML.
Порада : Донедавна Screaming Frog SEO Spider міг зупинятися або зависати при скануванні великого сайту. Тепер, коли сховище бази даних є стандартним налаштуванням, ви можете відновити обходи, щоб вибрати, де ви зупинилися. Крім того, ви також можете отримати доступ до URL-адрес у черзі. Це може дати вам уявлення про будь-які додаткові параметри або правила, які ви можете виключити для сканування великого сайту.

Як сканувати сайт, розміщений на старому сервері, або як сканувати сайт без збоїв
У деяких випадках старі сервери можуть не обробляти кількість URL-адрес за промовчанням за секунду. Ми рекомендуємо включити обмеження на кількість сканованих URL-адрес за секунду, щоб про всяк випадок не ускладнювати роботу сервера сайту. Найкраще, щоб клієнт знав, коли ви плануєте сканувати сайт, на випадок, якщо у нього може бути захист від невідомих користувачів агентів. З одного боку, їм може знадобитися внести в білий список ваш IP або власний агент (User-Agent), перш ніж ви будете сканувати сайт. У найгіршому випадку ви можете надіслати занадто багато запитів на сервер і ненавмисно завершити роботу сайту.
Щоб змінити швидкість сканування, виберіть Speed у меню Configuration та у спливаючому вікні виберіть максимальну кількість потоків, які мають працювати одночасно. У цьому меню також можна вибрати максимальну кількість URL-адрес, які запитуються за секунду.

Порада : Якщо ви виявите, що при скануванні виникає багато помилок сервера, перейдіть на вкладку Advanced в меню Spider Configuration і збільште значення Response Timeout і 5xx Response Retries, щоб отримати найкращі результати.

Як сканувати сайт, який вимагає кукі
Хоча пошукові роботи не приймають файли cookie, якщо ви скануєте сайт і хочете дозволити використання файлів cookie, просто виберіть Allow Cookies на вкладці Advanced у меню Spider Configuration.

Як сканувати, використовуючи інший користувальницький агент (User-Agent)
Щоб сканувати з використанням іншого користувача агента, виберіть User Agent в меню Configuration, потім виберіть пошукового бота зі списку, що випадає, або введіть потрібні рядки користувача агента.

Оскільки Google тепер орієнтована на мобільні пристрої, спробуйте просканувати сайт як смартфон Googlebot або змініть User-Agent, щоб він був як смартфон Googlebot. Це важливо з двох причин:
- Сканування сайту, що імітує користувача агента (user-agent) смартфон Googlebot, може допомогти визначити будь-які проблеми, що виникають у Google при скануванні та відображенні контенту вашого сайту.
- Використання модифікованої версії користувача агента смартфона Googlebot допоможе вам розрізняти ваші обходи та обходи Google при аналізі журналів сервера.
Як сканувати сторінки, які потребують аутентифікації
Коли Screaming Frog зустрічає сторінку, захищену паролем, з’являється спливаюче вікно, в якому ви можете ввести потрібне ім’я користувача та пароль.
Аутентифікація на основі форм є дуже потужною функцією і може вимагати JavaScript для ефективної роботи.
Примітка : автентифікацію на основі форм слід використовувати економно і тільки досвідченим користувачам. Сканер запрограмований так, що він клацає кожне посилання на сторінці, це може призвести до появи посилань для виходу з системи, створення повідомлень або навіть видалення даних.
Щоб керувати аутентифікацією, перейдіть до Configuration > Authentication.
Щоб вимкнути запити на аутентифікацію, скасуйте вибір Authentication на основі стандартів у вікні Authentication у меню Configuration.

Внутрішні посилання
Як отримати інформацію про всі внутрішні та зовнішні посилання на моєму сайті (якорний текст, директиви, посилання на сторінку тощо)
Якщо вам не потрібно перевіряти зображення, JavaScript, Flash або CSS на сайті, скасуйте вибір цих параметрів у меню Spider Configuration, щоб заощадити час та пам’ять.

Як тільки SEO Spider завершить сканування, використовуйте меню Bulk Export, щоб експортувати CSV All Links. Це надасть вам всі посилання, а також відповідний якірний текст, директиви і т.д.

Усі посилання можуть бути у великому звіті. Пам’ятайте про це під час експорту. Для великого сайту цей експорт може тривати кілька хвилин.
Для швидкого підрахунку кількості посилань на кожній сторінці перейдіть на вкладку Internal і відсортуйте Outlinks. Сторінки, де понад 100 посилань, можливо, потрібно буде переглянути.

Як знайти непрацюючі внутрішні посилання на сторінці або на сайті
Як і в попередньому пункті, скасуйте вибір JavaScript, Flash або CSS сайту в меню Spider Configuration, якщо вам не потрібно перевіряти зображення.
Після того, як SEO Spider завершить сканування, відсортуйте результати вкладки Internal за Status Code. Будь-який 404, 301 або інший код стану будуть легко доступні для перегляду.
Натиснувши на будь-яку окрему URL-адресу в результатах сканування, ви побачите зміну інформації в нижньому вікні програми. Натиснувши на вкладку In Links у нижньому вікні, ви побачите список сторінок, які посилаються на вибраний URL, а також якірний текст та директиви, які використовуються у цих посиланнях. Ви можете використовувати цю функцію для визначення сторінок, на яких потрібно оновити внутрішні посилання.
Щоб експортувати повний список сторінок, які містять непрацюючі або перенаправлені посилання, виберіть Redirection (3xx) In Links або Client Error (4xx) In Links або Server Error (5xx) In Links у меню Advanced Export, і ви отримаєте CSV-експорт даних.
Щоб експортувати повний список сторінок, які містять посилання, що не працюють або перенаправлені, відвідайте меню Bulk Export. Прокрутіть вниз до коду відповідей та перегляньте наступні звіти:
- No Response Inlinks;
- Redirection (3xx) Inlinks;
- Redirection (JavaScript) Inlinks;
- Redirection (Meta Refresh) Inlinks;
- Client Error (4xx) Inlinks;
- Server Error (5xx) Inlinks.

Перегляд усіх цих звітів повинен дати вам адекватне уявлення про те, які внутрішні посилання слід оновити, щоб вони вказували на канонічну версію URL та ефективно розподіляли якісні посилання.
Як знайти непрацюючі вихідні посилання на сторінці або на сайті (або всі вихідні посилання в цілому)
Після скасування вибору Check Images, Check CSS, Check JavaScript та Check SWF у налаштуваннях Spider Configuration переконайтеся, що Check External Links залишається вибраним.
Після того, як SEO Spider завершить сканування, натисніть на вкладку External у верхньому вікні, відсортуйте за Status Code Ви легко зможете знайти URL з кодом стану, відмінним від 200. Після натискання на будь-який окремий URL, проскануйте результати, а потім, натиснувши на вкладку In Links у нижньому вікні, ви побачите список сторінок, які вказують на обрану URL-адресу. Ви можете використовувати цю функцію для визначення сторінок, на яких потрібно оновити вихідні посилання.
Щоб експортувати повний список вихідних посилань, натисніть External Links на вкладці Bulk Export.

Щоб отримати повний список усіх розташування та тексту прив’язки вихідних посилань, виберіть All Outlinks у меню Bulk Export. Звіт All Outlinks також включатиме вихідні посилання на ваші субдомени. Якщо ви бажаєте виключити свій домен, скористайтеся вищезгаданим звітом External Links.
Як знайти посилання, які перенаправляються
Після завершення сканування виберіть вкладку Response Codes в основному інтерфейсі користувача і виконайте фільтрацію за кодом стану. Оскільки Screaming Frog використовує регулярні вирази для пошуку, відправте як фільтр наступні критерії: 301 | 302 | 307. Це має дати вам досить солідний список усіх посилань, які поверталися з будь-яким перенаправленням, незалежно від того, чи був контент постійно переміщений, знайдений і перенаправлений, або тимчасово перенаправлений через налаштування HSTS (це ймовірна причина 307 перенаправлень у Screaming Frog).
Сортуйте за Status Code, і ви зможете розбити результати за типом. Натисніть вкладку In Links у нижньому вікні, щоб переглянути всі сторінки, на яких використовується посилання для перенаправлення.
Якщо ви експортуєте безпосередньо з цієї вкладки, побачите лише ті дані, які відображаються у верхньому вікні (оригінальний URL, код стану і куди він перенаправляється).
Щоб експортувати повний список сторінок, що містять перенаправлені посилання, потрібно буде вибрати Redirection (3xx) In Links у меню Advanced Export. Це поверне CSV, який включає місце розташування всіх ваших перенаправлених посилань. Щоб відобразити лише внутрішні перенаправлення, відфільтруйте стовпець Destination у CSV, щоб увімкнути лише ваш домен.
Порада : Використовуйте функцію VLOOKUP (ВПР) між двома вищезгаданими файлами експорту, щоб зіставити стовпці Source та Destination із остаточним розташуванням URL-адреси.
Приклад формули:
= ВПР ([@ Destination], ‘response_codes_redirection_ (3xx).csv’ $ A $ 3: $ F $ 50,6, FALSE)
Де response_codes_redirection_ (3xx) .csv – це файл CSV, що містить URL-адреси перенаправлення, а 50 – кількість рядків у цьому файлі.
Для чого потрібні дані про посилання
Грамотний розподіл внутрішніх посилань може підвищити ефективність пошукового просування, особливо коли ви займаєтеся стратегічним підходом до розподілу PageRank та якісних посилань, ранжування ключових слів та прив’язки до ключових слів.
Контент сайту
Як визначити сторінки з неінформативним контентом
Після завершення сканування SEO Spider перейдіть на вкладку Internal, відфільтруйте їх HTML, потім прокрутіть вправо до стовпця Word Count. Сортуйте стовпець Word Count за спаданням, щоб знайти сторінки з низьким змістом тексту. Ви можете перетягнути стовпець Word Count вліво, щоб краще зіставити значення низької кількості слів із відповідними URL-адресами. Натисніть Export на вкладці Internal, якщо ви надаєте перевагу замість цього керувати даними в CSV.
Як отримати список посилань на зображення на певній сторінці
Якщо ви вже переглянули весь сайт або підпапку, просто виберіть сторінку у верхньому вікні, а потім натисніть вкладку Image Info у нижньому вікні, щоб переглянути всі зображення, знайдені на цій сторінці. Зображення будуть перераховані у стовпці To.
Порада : Клацніть правою кнопкою миші будь-який запис у нижньому вікні, щоб скопіювати або відкрити URL-адресу.
Крім того, ви можете переглядати зображення на одній сторінці, скануючи тільки цей URL. Переконайтеся, що в налаштуваннях конфігурації SEO Spider задана глибина сканування 1, після сканування сторінки перейдіть на вкладку Images, і ви побачите всі зображення, знайдені screaming frog.
Як знайти зображення, в яких немає тексту alt або зображення з довгим текстом alt
По-перше, ви повинні переконатися, що у меню Spider Configuration вибрано Check Images. Після того, як SEO Spider перестав аналізувати, перейдіть на вкладку Images і відфільтруйте по Missing Alt Text або Alt Text Over 100 Characters. Ви можете знайти сторінки, де знаходиться будь-яке зображення, натиснувши вкладку Image Info в нижньому вікні. Сторінки будуть перераховані у стовпці From.
Нарешті, якщо ви віддаєте перевагу CSV, використовуйте меню Bulk Export, щоб експортувати All Images або Images Missing Alt Text Inlinks, щоб побачити повний список зображень, де вони знаходяться, і будь-який пов’язаний з ним текст alt або проблеми з alt Text.

Використовуйте праву бічну панель, щоб перейти до розділу зображень для обходу. Тут можна легко експортувати список усіх зображень, пропущених текстом alt.

Як знайти кожен файл CSS на моєму сайті
У меню Spider Configuration виберіть Crawl і Store CSS перед скануванням, після завершення сканування відфільтруйте результати на вкладці Internal за допомогою CSS.

Як знайти кожен файл JavaScript на сайті
У меню Spider Configuration виберіть Check JavaScript перед скануванням, після завершення сканування відфільтруйте результати на вкладці Internal по JavaScript.
Як визначити всі плагіни jQuery, які використовуються на сайті, і на яких сторінках вони використовуються
По-перше, переконайтеся, що у меню Spider Configuration вибрано Check JavaScript. Після того, як SEO Spider завершив сканування, відфільтруйте вкладку Internal JavaScript, потім знайдіть jquery. Це надасть вам список файлів плагінів. Сортуйте список Address для більш зручного перегляду за потреби, потім перегляньте InLinks у нижньому вікні або експортуйте дані в CSV, щоб знайти сторінки, де використовується файл. Вони будуть у стовпці From.
Крім того, ви можете використовувати меню Advanced Export, щоб експортувати CSV All Links і відфільтрувати стовпець Destination, щоб відображалися лише URL-адреси з jquery.
Порада : Не всі jQuery плагіни шкідливі для SEO. Якщо ви бачите, що сайт використовує jQuery, найкраще переконатися, що контент, який ви хочете проіндексувати, включений у джерело сторінки та обслуговується під час завантаження сторінки, а не після. Якщо ви все ще не впевнені, встановіть плагін Google для отримання додаткової інформації про те, як він працює.
Як визначити місця із вбудованим flash
У меню Spider Configuration виберіть Check SWF перед скануванням, після завершення сканування відфільтруйте результати на вкладці Internal по Flash.
Це стає все більш важливим, щоб знаходити та ідентифікувати контент, який постачається Flash, та пропонувати альтернативний код для нього. Flash поступово старіє для Chrome. Тому цей функціонал дійсно потрібно використовувати, щоб визначити, чи є проблеми з критичним контентом і Flash на сайті.
Примітка : цей метод знаходить лише файли .SWF, які пов’язані на сторінці. Якщо флеш-пам’ять завантажується через JavaScript, вам потрібно використовувати фільтр користувача.
Як знайти будь-які внутрішні PDF-файли
Після завершення сканування в Screaming Frog відфільтруйте результати на вкладці Internal PDF.
Як зрозуміти сегментацію контенту всередині сайту чи групи сторінок
Якщо ви хочете знайти на своєму сайті сторінки з певним типом контенту, встановіть спеціальний фільтр для HTML коду, унікального для цієї сторінки. Це потрібно зробити перед запуском screaming frog.
Як знайти сторінки з кнопками соціальних мереж
Щоб знайти сторінки, які містять кнопки соціальних мереж, потрібно встановити власний фільтр перед запуском. Щоб встановити фільтр користувача, перейдіть в меню Configuration і натисніть Custom. Звідти введіть будь-який фрагмент коду вихідного коду сторінки.

У цьому прикладі фільтр для facebook.com/plugins/like.php.
Як знайти сторінки, які використовують iframes
Щоб знайти сторінки, які використовують iframe, встановіть фільтр для < iframe перед запуском.
Як знайти сторінки, які містять вбудований відео або аудіо контент
Щоб знайти сторінки, що містять вбудоване відео або аудіоконтент, встановіть спеціальний фільтр для фрагмента коду вбудовування для Youtube або іншого медіаплеєра, який використовується на сайті.

Метадані та директиви
Як ідентифікувати сторінки з довгими заголовками сторінок, метаописами або URL-адресами
Після завершення сканування, перейдіть на вкладку Page Titles і відфільтруйте Over 65 Characters, щоб побачити занадто довгі заголовки сторінок. Ви можете зробити те саме на вкладці Meta Description або на вкладці URI.

Як знайти повторювані заголовки сторінок, метаопису або URL
Після того, як SEO Spider перестав сканувати, перейдіть на вкладку Page Titles, потім виберіть Duplicate. Ви можете зробити те саме на вкладках Meta Description або URI.

Як знайти дубльований контент або URL-адреси, які необхідно переписати/перенаправити/канонізувати
Після того, як SEO Spider завершив сканування, перейдіть на вкладку URI, потім відфільтруйте Underscores, Uppercase або Non ASCII Characters, щоб переглянути URL, які потенційно можуть бути переписані в більш стандартну структуру. Виберіть Duplicate, і ви побачите всі сторінки з кількома версіями URL-адреси. Відфільтруйте Parameters, і ви побачите URL-адреси, що містять параметри.

Крім того, якщо ви перейдете на вкладку Internal, відфільтруєте HTML і прокрутите стовпець Hash в крайньому правому кутку, ви побачите унікальні серії букв і цифр для кожної сторінки. Якщо ви натиснете Export, ви можете використовувати умовне форматування в Excel, щоб виділити значення, що дублюються в цьому стовпці, в кінцевому рахунку, будуть вам показані сторінки, які ідентичні і вимагають рішення.

Як визначити всі сторінки, що містять мета-директиви, наприклад: nofollow / noindex / noodp / canonical і т.д.
Після того, як SEO Spider закінчив перевірку, натисніть вкладку Directives. Щоб побачити тип директиви, просто прокрутіть вправо, щоб побачити, які стовпці заповнені, або використовуйте фільтр, щоб знайти будь-який з наступних тегів:
- index;
- noindex;
- follow;
- nofollow;
- noarchiv;
- nosnippet;
- noodp;
- noydir;
- noimageindex;
- notranslate;
- unavailable_after;
- refresh.

Як перевірити коректність роботи файлу robots.txt
За замовчуванням Screaming Frog виконуватиме вимоги robots.txt. Як пріоритет він слідуватиме директивам, зробленим спеціально для користувача агента (user agent) Screaming Frog. Якщо для користувача агента (user-agent) Screaming Frog немає ніяких директив, то SEO Spider буде дотримуватися будь-яких директив для робота Googlebot, а якщо немає спеціальних директив для робота Googlebot, він буде дотримуватися глобальних директив для всіх користувальницьких агентів.
SEO Spider буде дотримуватися лише одного набору директив, тому, якщо існують правила, встановлені спеціально для Screaming Frog, він дотримуватиметься лише цих правил, а не правил для робота Google або будь-яких глобальних правил. Якщо ви хочете заблокувати певні частини сайту від SEO Spider, використовуйте звичайний синтаксис robots.txt з власним агентом Screaming Frog SEO Spider. Якщо ви хочете ігнорувати robots.txt, просто оберіть цю опцію в налаштуваннях Spider Configuration.
Configuration > Robots.txt > Settings

Як знайти або перевірити розмітку схеми чи інші мікродані на моєму сайті
Щоб знайти кожну сторінку, яка містить розмітку схеми або будь-які інші мікродані, вам потрібно використовувати фільтри. Просто натисніть Custom → Search у меню конфігурації та введіть потрібний елемент footprint.
Щоб знайти кожну сторінку, що містить розмітку схеми, просто додайте наступний фрагмент коду в фільтр користувача: itemtype = http://schema.org
Щоб знайти конкретний тип розмітки, потрібно бути більш конкретним. Наприклад, за допомогою фільтра для ‹span itemprop = ratingValue› ви отримаєте всі сторінки, що містять розмітку схеми для оцінок.
Починаючи з Screaming Frog 11.0, Spider SEO також пропонує нам можливість сканувати, вилучати та перевіряти структуровані дані безпосередньо із сканування. Перевіряйте будь-які структуровані дані JSON-LD, Microdata або RDFa відповідно до рекомендацій Schema.org та специфікацій Google в режимі реального часу під час сканування. Щоб отримати доступ до інструментів перевірки структурованих даних, виберіть опції Config > Spider > Advanced.

Тепер у головному інтерфейсі є вкладка Structured Data, яка дозволить вам перемикатися між сторінками, що містять структуровані дані, та які можуть мати помилки або попередження перевірки:

Ви також можете виконати масовий експорт проблем зі структурованими даними, відвідавши Reports > Structured Data > Validation Errors & Warnings.

Карта сайту
Як створити XML Sitemap
Після того, як SEO Spider завершить сканування вашого сайту, натисніть меню Siteamps та виберіть XML Sitemap.

Відкривши налаштування конфігурації XML-карти сайту, ви можете включати або виключати сторінки за кодом відповідей, останніми змінами, пріоритетами, частотою змін, зображеннями тощо. Д. За замовчуванням Screaming Frog включає лише 2xx URL-адрес, але це правило можна виправити.

В ідеалі, ваша карта сайту XML повинна містити лише 200 статусних, одиничних, кращих (канонічних) версій кожної URL-адреси, без параметрів або інших факторів, що дублюють. Після внесення змін натисніть OK. Файл XML-файлу сайту буде завантажений на ваш пристрій і дозволить вам редагувати угоду про імена на вашу думку.
Створення XML-файлу Sitemap шляхом завантаження URL-адрес
Ви також можете створити карту сайту XML, завантаживши URL-адресу з існуючого файлу або вставивши вручну до Screaming Frog.
Змініть Mode з Spider на List і натисніть на список Upload, що випадає, щоб вибрати будь-який з варіантів.


Натисніть кнопку Start і Screaming Frog скануватиме завантажені URL-адреси. Після сканування URL ви наслідуватимете той самий процес, який зазначено вище.
Як перевірити мій існуючий XML Sitemap
Ви можете легко завантажити існуючу XML-картку або індекс картки сайту, щоб перевірити наявність помилок або невідповідностей при скануванні.
Перейдіть в меню Mode в Screaming Frog та виберіть List. Потім натисніть Upload у верхній частині екрана, виберіть Download Sitemap або Download Sitemap Index, введіть URL-адресу картки сайту та почніть сканування. Як тільки SEO Spider закінчить сканування, ви зможете знайти будь-які перенаправлення, 404 помилки, дубльовані URL-адреси та багато іншого. Ви можете легко експортувати та виявлені помилки.
Визначення відсутніх сторінок у XML Sitemap
Ви можете налаштувати параметри сканування, щоб виявляти та порівнювати URL-адреси у ваших XML-файлах сайту з URL-адресами в межах вашого сайту.
Перейдіть в Configuration -> Spider в головній навігації, і внизу є кілька опцій для XML-карт сайтів – Auto discover XML sitemaps через файл robots.txt або вручну введіть посилання XML-карти сайту в поле. *Important note – якщо файл robots.txt не містить правильних цільових посилань на всі XML-карти сайту, які ви хочете сканувати, ви повинні ввести їх вручну.

Після оновлення налаштувань сканування XML-файлу Sitemap перейдіть до Crawl Analysis у навігації, потім натисніть Configure і переконайтеся, що кнопка Sitemaps позначена. Спочатку запустіть повне сканування сайту, потім поверніться до Crawl Analysis та натисніть Start.

Після завершення аналізу сканування ви зможете побачити будь-які розбіжності при скануванні, такі як URL-адреси, виявлені в рамках повного сканування сайту, які відсутні на карті сайту XML.
Загальні проблеми
Як визначити, чому певні розділи сайту не індексуються або ранжуються
Бажаєте знати, чому деякі сторінки не індексуються? По-перше, переконайтеся, що вони були випадково поміщені у файл robots.txt або позначені як noindex. Потім ви повинні переконатися, що SEO Spider може дістатися сторінок, перевіривши ваші внутрішні посилання. Сторінку, яка не має внутрішніх посилань на вашому сайті, часто називають “сиротами” (Orphaned Page).
Щоб виявити втрачені сторінки, виконайте такі дії:
Перейдіть в Configuration -> Spider в головній навігації, і внизу є кілька опцій для XML-карт сайтів – Auto discover XML sitemaps через файл robots.txt або вручну введіть посилання XML-карти сайту в поле. *Important note – якщо файл robots.txt не містить правильних цільових посилань на всі XML-карти сайту, які ви хочете сканувати, ви повинні ввести їх вручну.
Перейдіть до Configuration → API Access → Google Analytics – використовуючи API, ви можете отримати аналітичні дані для конкретного облікового запису та перегляду. Щоб знайти безгоспні сторінки з органічного пошуку, переконайтеся, що вони поділені на органічний трафік.

Ви також можете перейти до розділу General → Crawl New URLs Discovered In Google Analytics, якщо ви хочете, щоб URL-адреси, виявлені в GA, були включені у ваш повний обхід сайту. Якщо це не увімкнено, ви зможете переглядати тільки нові URL-адреси, витягнуті з GA, у звіті Orphaned Pages.

Перейдіть до Configuration → API Access → Google Search Console – використовуючи API, ви можете отримати дані GSC для конкретного облікового запису та перегляду. Щоб знайти безгоспні сторінки, ви можете шукати URL-адреси, на яких отримані кліки та покази, які не включені до вашого перегляду. Ви також можете перейти до розділу General → Crawl New URLs Discovered In Google Search Console, якщо ви хочете, щоб URL-адреси, виявлені в GSC, були включені у ваш повний обхід сайту. Якщо цей параметр не увімкнено, ви зможете переглядати лише нові URL-адреси, витягнуті з GSC, у звіті Orphaned Pages.
Проскануйте весь веб-сайт. Після завершення сканування перейдіть у Crawl Analysis -> Start і дочекайтеся його завершення.
Перегляньте втрачені URL-адреси на кожній із вкладок або виконайте Bulk Expor всіх втрачених URL-адрес, перейшовши в Reports → Orphan Pages.

Якщо у вас немає доступу до Google Analytics або GSC, ви можете експортувати список внутрішніх URL-адрес у вигляді файлу .CSV, використовуючи фільтр HTML на вкладці Internal.
Відкрийте файл CSV і на другому аркуші вставте список URL-адрес, які не індексуються або погано ранжуються. Використовуйте VLOOKUP, щоб побачити, чи були URL-адреси у вашому списку на другому аркуші знайдені під час сканування.
Як знайти повільні сторінки на моєму сайті
Після того, як SEO Spider завершив сканування, перейдіть на вкладку Response Codes і відсортуйте стовпцем Response Time за зростанням, щоб знайти сторінки, які можуть страждати від повільної швидкості завантаження.

Як знайти шкідливе ПЗ або спам на моєму сайті
По-перше, вам необхідно ідентифікувати слід шкідливого програмного забезпечення або спаму. Далі в меню Configuration натисніть Custom → Search і введіть потрібний елемент, який ви шукаєте.

Можна ввести до 10 різних фільтрів для сканування. Нарешті, натисніть OK та продовжуйте сканування сайту або списку сторінок.

Коли SEO Spider завершить сканування, виберіть вкладку Custom у верхньому вікні, щоб переглянути усі сторінки, що містять відбиток. Якщо ви ввели більше одного фільтра користувача, ви можете переглянути кожен, змінивши фільтр за результатами.
PPC та аналітика
Як перевірити список URL-адрес PPC навалом
Збережіть список у форматі .txt або .csv, а потім змініть налаштування Mode на List.

Потім виберіть файл для завантаження та натисніть Start або вставте свій список вручну у Screaming Frog. Перегляньте код стану кожної сторінки, перейшовши на вкладку Internal.
Зачистка
Як очистити метадані для списку сторінок
Отже, ви зібрали багато URL, але вам потрібна додаткова інформація про них? Встановіть режим List, а потім завантажте список URL-адрес у форматі .txt або .csv. Після того, як SEO Spider буде готовий, ви зможете побачити код стану, вихідні посилання, кількість слів і, звичайно, метадані для кожної сторінки у вашому списку.
Як очистити веб-сайт для всіх сторінок, які містять певний розмір?
По-перше, вам потрібно визначити слід. Потім у меню Configuration натисніть Custom → Search або Extraction і введіть елемент, який ви шукаєте.

Ви можете ввести до 10 різних слідів сканування. Нарешті, натисніть OK та продовжуйте сканування сайту або списку сторінок. У наведеному нижче прикладі я хотів знайти всі сторінки з написом ПОСЛУГИ у розділі цін, тому я знайшов та скопіював HTML-код із вихідного коду сторінки.

Коли SEO Spider завершить перевірку, виберіть вкладку Custom у верхньому вікні, щоб переглянути усі сторінки, що містять відбиток. Якщо ви ввели більше одного фільтра користувача, ви можете переглянути кожен, змінивши фільтр за результатами.
Нижче наведено деякі додаткові загальні сліди, які ви можете отримати з веб-сайтів, які можуть бути корисні для ваших аудитів SEO:
- http:// schema .org – знайти сторінки, які містять schema.org;
- youtube.com/embed/|youtu.be|<video|player.vimeo.com/video/|wistia.(com|net)/embed|sproutvideo.com/embed/|view.vzaar.com|dailymotion.com/ embed/| Players.brightcove.net/ | play.vidyard.com/ | kaltura.com/ (p | kwidget) / – знайти сторінки, що містять відеоконтент.
Порада : Якщо ви отримуєте дані про продукт з клієнтського сайту, ви можете заощадити деякий час, попросивши клієнта витягти їх безпосередньо з бази даних. Описаний метод призначений для сайтів, до яких у вас немає прямого доступу.
Перезапис URL
Як знайти та видалити ідентифікатор сеансу або інші параметри з просканованих URL-адрес
Щоб ідентифікувати URL-адресу з ідентифікаторами сеансів або іншими параметрами, просто перегляньте ваш сайт з налаштуваннями за замовчуванням. Коли SEO Spider закінчив аналізувати, натисніть на вкладку URI і виберіть пункт Parameters, щоб переглянути всі URL-адреси, що містять параметри.
Щоб видалити параметри, які відображаються для перегляданих URL-адрес, виберіть URL Rewriting в меню конфігурації, а потім на вкладці Remove Parameters натисніть Add, щоб додати всі параметри, які потрібно видалити з URL-адрес, і натисніть OK. Вам доведеться знову запустити Screaming Frog із цими налаштуваннями, щоб відбувся перезапис.

Як переписати проскановані URL-адреси (наприклад, замінити .com на .co.uk або написати всі URL-адреси малими літерами)
Щоб переписати будь-яку URL, яку ви скануєте, виберіть URL Rewriting в меню Configuration, а потім на вкладці Regex Replace натисніть Add, щоб додати RegEx для того, що ви хочете замінити.

Після того, як ви додали всі потрібні правила, ви можете перевірити їх на вкладці Test, ввівши тестову URL-адресу в поле URL перед rewriting. URL after rewriting буде автоматично оновлюватися відповідно до ваших правил.

Якщо ви хочете встановити правило, згідно з яким усі URL-адреси повертаються в нижньому регістрі, просто оберіть Lowercase discovered URLs на вкладці Options. Це видаляє будь-яке дублювання URL-адресами з великими літерами під час сканування.

Пам’ятайте, що вам доведеться запустити SEO Spider із цими налаштуваннями, щоб перезапис URL відбувся.
Дослідження ключових слів
Як дізнатися, які сторінки мої конкуренти цінують найбільше
Конкуренти намагатимуться поширити популярність посилань та залучити трафік на свої найцінніші сторінки, посилаючись на них усередині. Будь-який SEO-орієнтований конкурент, ймовірно, також посилатиметься на важливі сторінки з блогу своєї компанії. Знайдіть цінні сторінки вашого конкурента, просканувавши їх сайт, а потім відсортувавши вкладку Internal по стовпцю Inlinks за зростанням, щоб побачити, які сторінки мають більше внутрішніх посилань.

Щоб переглянути сторінки, посилання на які є у блозі вашого конкурента, скасуйте вибір Check links outside folder у меню Spider Configuration та перегляньте папку/піддомен блогу. Потім на вкладці External фільтруйте результати за допомогою пошуку по URL основного домену. Перейдіть до крайнього правого краю та відсортуйте список по стовпцю Inlinks, щоб побачити, які сторінки пов’язані найчастіше.

Порада : Перетягніть стовпці ліворуч або праворуч, щоб покращити перегляд даних.
Як дізнатися, який якірний текст використовують мої конкуренти для внутрішніх посилань
У меню Bulk Export виберіть All Anchor Text, щоб експортувати файл CSV, що містить весь текст прив’язки на сайті, де він використовується і з чим він пов’язаний.

Як дізнатися які метатеги keywords (якщо вони є) конкуренти додали на свої сторінки
Після того, як SEO Spider закінчив сканувати, перегляньте вкладку Meta Keywords, щоб побачити їх, знайдені для кожної сторінки. Сортуйте по стовпцю Meta Keyword 1, щоб розмістити алфавітний список і візуально відокремити порожні записи або просто експортувати весь список.
Створення посилань
Як проаналізувати список передбачуваних посилань
Якщо ви створили список URL-адрес, які потрібно перевірити, ви можете завантажити та відсканувати їх у режимі List, щоб зібрати більше інформації про сторінки. Після завершення сканування, перевірте коди стану на вкладці Response Codes і перегляньте вихідні посилання, типи посилань, текст прив’язки та директиви nofollow на вкладці Outlinks у нижньому вікні. Це дасть вам уявлення про те, на які сайти посилаються ці сторінки та як. Щоб переглянути вкладку Outlinks, переконайтеся, що у верхньому вікні обраний URL, який вас цікавить.
Звичайно, ви захочете використовувати фільтр користувача, щоб визначити, чи посилаються ці сторінки вже на вас.

Ви також можете експортувати повний список вихідних посилань, натиснувши All Outlinks до Bulk Export Menu. Це не тільки надасть вам посилання на зовнішні сайти, але й покаже всі внутрішні посилання на окремих сторінках вашого списку.

Як знайти непрацюючі посилання для розширення можливостей
Отже, ви знайшли сайт, з якого бажаєте отримати посилання? Використовуйте Screaming Frog, щоб знайти непрацюючі посилання на потрібній сторінці або на сайті в цілому, потім зверніться до власника сайту, запропонувавши свій сайт як заміну непрацюючого посилання, де це застосовно, або просто вкажіть на непрацююче посилання як знак доброї волі.
Як перевірити мої зворотні посилання та переглянути текст прив’язки
Завантажте свій список зворотних посилань та запустіть SEO Spider у режимі List. Потім експортуйте повний список вихідних посилань, натиснувши All Out Links до Advanced Export Menu. Це надасть вам URL-адреси та анкорний текст / текст alt для всіх посилань на цих сторінках. Потім ви можете використовувати фільтр у стовпці Destination CSV, щоб визначити, чи пов’язаний ваш сайт і який текст прив’язки / текст alt включений.
Як переконатися, що посилання видаляються на запит у процесі очищення
Встановіть фільтр користувача, що містить URL-адресу вашого кореневого домену, потім завантажте список зворотних посилань і запустіть SEO Spider в режимі List. Коли SEO Spider завершить сканування, виберіть вкладку Custom, щоб переглянути всі сторінки, які досі посилаються на вас.
додаткова інформація

Чи знаєте ви, що, клацнувши правою кнопкою миші на будь-якому URL у верхньому вікні ваших результатів, ви можете виконати будь-яку з наступних дій?
- Копіювати або відкрити URL-адресу;
- Повторно сканувати URL або видалити його зі свого сканування;
- Експортувати інформацію про URL, посилання, вихідні посилання або інформацію про зображення для цієї сторінки
- Перевірити індексацію сторінки в Google;
- Перевірити зворотні посилання на сторінку Majestic, OSE, Ahrefs і Blekko.
- Подивитися на кешовану версію/дату кеша сторінки;
- дивитися старі версії сторінки;
- Перевірити HTML-код сторінки
- відкрити robots.txt для домену, на якому знаходиться сторінка;
- Пошук інших доменів на тому ж IP.

Аналогічно, у нижньому вікні, клацнувши правою кнопкою миші, ви можете скопіювати або відкрити URL-адресу в стовпці To для вибраного рядка.
Як редагувати метадані
Режим SERP дозволяє переглядати фрагменти SERP на пристрої, щоб візуально показати, як ваші метадані відображатимуться в результатах пошуку.
-
Завантажте URL, заголовки та метаописи у Screaming Frog, використовуючи документ .CSV або Excel.
Якщо ви вже провели сканування свого сайту, можете експортувати URL-адреси, перейшовши в Reports → SERP Summary. Це легко відформатує URL та мета, які ви хочете завантажити та відредагувати.
- Mode → SERP → Upload File.
- Редагуйте метадані в Screaming Frog.

Масовий експорт оновлених метаданих для відправки безпосередньо розробникам для оновлення.
Як сканувати JavaScript-сайту
Все частіше веб-сайти створюються з використанням таких JavaScript-фреймворків, як Angular, React і т.д. Google настійно рекомендує використовувати рішення для рендерингу, оскільки робот Googlebot все ще намагається сканувати вміст JavaScript. Якщо ви визначили сайт, створений за допомогою JavaScript, дотримуйтесь наведених нижче інструкцій, щоб сканувати сайт.
Configuration → Spider → Rendering → JavaScript

Змініть настройки рендерингу в залежності від того, що ви шукаєте. Ви можете налаштувати час очікування, розмір вікна (мобільний, планшет, робочий стіл тощо)
Натисніть OK та скануйте веб-сайт.
У нижній частині навігації клацніть вкладку Rendered Page, щоб побачити, як відображається сторінка. Якщо ваша сторінка не відображається належним чином, перевірте наявність заблокованих ресурсів або збільште ліміт часу очікування налаштувань конфігурації. Якщо жоден із варіантів не допоможе вирішити, як ваша сторінка відображається, можливо, виникне серйозніша проблема.

Ви можете переглянути та масово експортувати будь-які заблоковані ресурси, які можуть вплинути на сканування та візуалізацію вашого сайту, перейшовши до Bulk Export → Response Codes.

Перегляд оригінального HTML та візуалізованого HTML
Якщо ви хочете порівняти необроблений HTML і візуалізований HTML, щоб виявити будь-які невідповідності або переконатися, що важливий контент знаходиться в DOM, перейдіть в Configuration → Spider -> Advanced і натисніть hit store HTML і store rendered HTML.

У нижньому вікні можна побачити необроблений і візуалізований HTML. Це може допомогти виявити проблеми з тим, як ваш контент відображається та проглядається сканерами.

На закінчення
Ми сподіваємося, що цей посібник дасть вам найкраще уявлення про те, які можливості вам доступні в Screaming Frog, а також допоможе заощадити години роботи.
Іванина Роман



